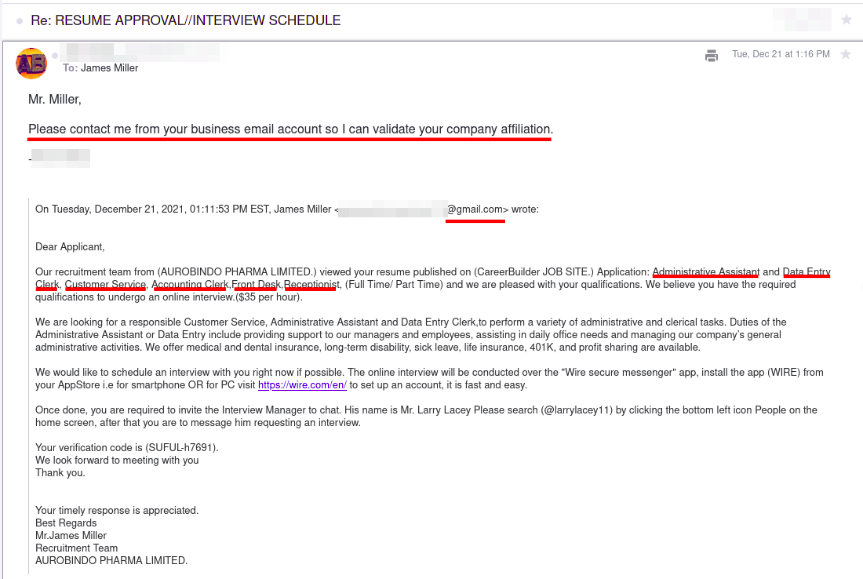
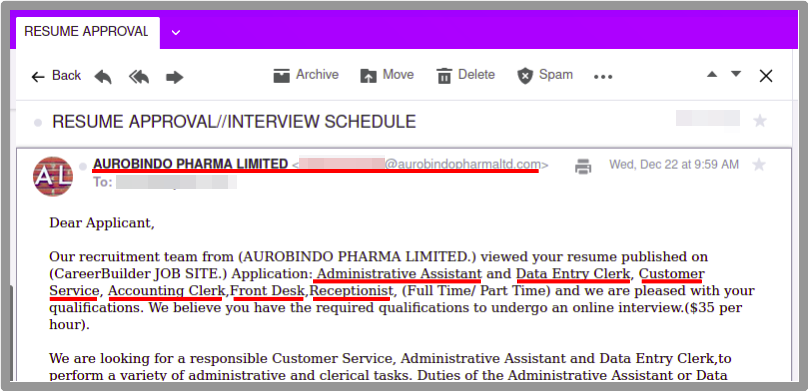
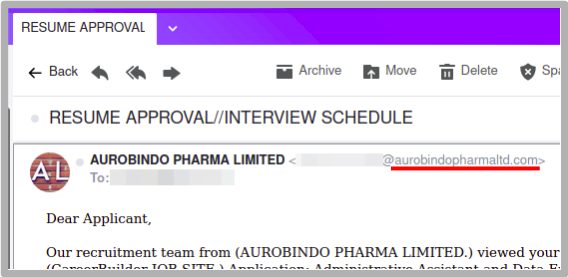
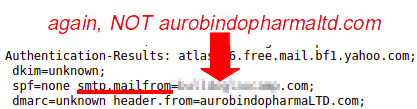
Use groups to maintain ACLs.
Digital information has creators, owners, editors, publishers, and consumers. Dependent on the information it has different approved audiences; public, creator’s organization, leadership, functional group, etc. And the audiences can be subdivided dependent on the level of authority they have; read only, modify, create, etc.
How to control who sees what? Accounts need to access, change and create information. At least some of that information will be in the cloud, either your own, or space and services hosted and invoiced monthly, or a combination. Access to public and private domains should be convenient for authorized users on supported platforms.
And be sure to classify the information! The public stuff has access control set so everyone can see it. Everything else needs to be someplace private. Add in an approval process for material to go public. Devise a rights scheme for the private domain. Owners, Editors, Readers.
Add to all this a folder hierarchy that supports the envisioned rights and document access should be understandable, maintainable, and auditable (with proper auditing enabled).
What’s the *perfect* configuration for all of this? As far as I’ve discovered, there isn’t one. Please comment with any reference if you know of some.
The perfect configuration is one that is maintained per business needs. Maintained is really the operative requirement.
Default everything to private so only authors have access to their own work?
How to collaborate? Give others read/edit access as needed per instructions from owner? That gets into LOTS and LOTS of ACL changes as people change in the organization, to say nothing of sun setting access. When should those collaborators have edit removed, or what about even read?
If rights are granted by individual account then this creates lots of future unidentified GUIDs in ACLs as accounts are removed, or lots of maintenance to find the accounts in the ACLs and remove them before the account is removed.
And, even if accounts aren’t removed because the person is changing position so should have access to different files, if requires lots of maintenance as people move from position to position.
Default everything to public read only and authors have edit access to their own work?
This limits the need to provide access to individual accounts unless the account needs edit rights to a document. If the same approach is taken to granting edit rights as was suggested for read rights above, then the same situation with maintaining access occurs except this time only for editors. Likely a lesser support burden but nonetheless still one that is likely to leave orphaned GUIDs in the ACLs.
Manage access by group!
Create Reader and Editor groups. As many as needed to accommodate each of the various groups needing access to the folders and files. Add and remove accounts from the groups as needed.
Managing access by group won’t cover all the needs. It may still be necessary to put individual accounts into the ACLs. However managing by group will limit the need to put individual accounts into the ACLs, and it will help make clear the rights if group name conventions are used to make the purpose of the group more apparent, e.g., AccountsPayableReaders, AccountsPayableEditors.
This can be taken further. If the two groups above have relatively steady membership then accounts that have limited need to access as readers or editors can be added to groups within these groups making it apparent the account holder has temporary access. The nested groups could be TmpAccountsPayableReaders, and TmpAccountsPayableEditors.
In the end..
There is not a “perfect” no maintenance system to manage and control access rights. Groups are certainly recommended over individual accounts. So long as the organization experiences changes that should affect document access it will be necessary to maintain ACLs.
The goal really is to limit the work needed to know what access is granted to which accounts, to maintain proper access, and use a method that is sustainable.
Groups really are the solution. Groups and a well established process to identify, classify, and assign rights to information throughout its lifecycle from creation to retirement.