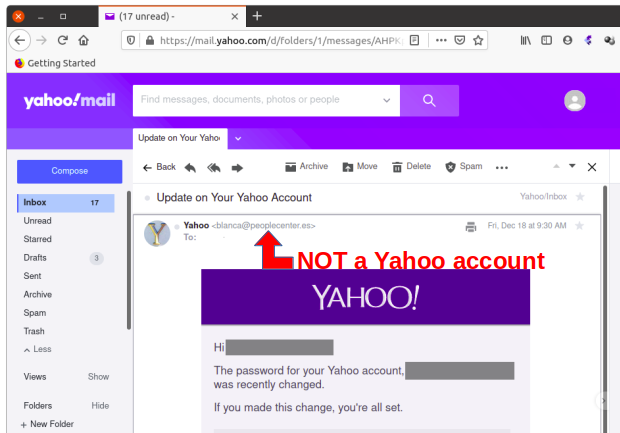
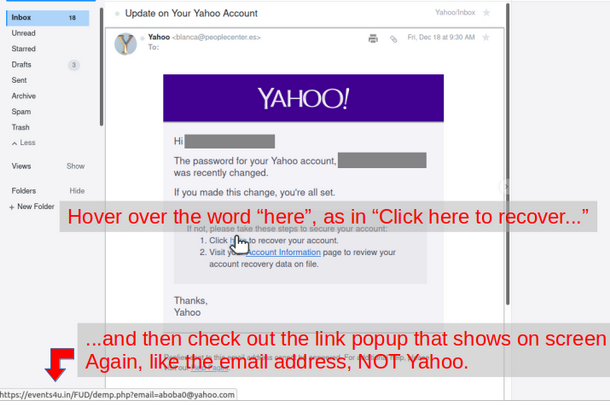
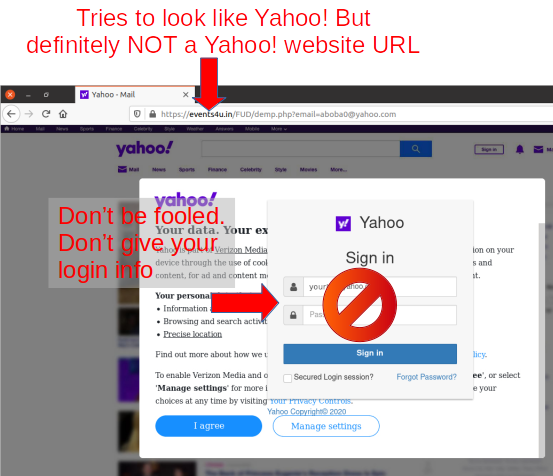
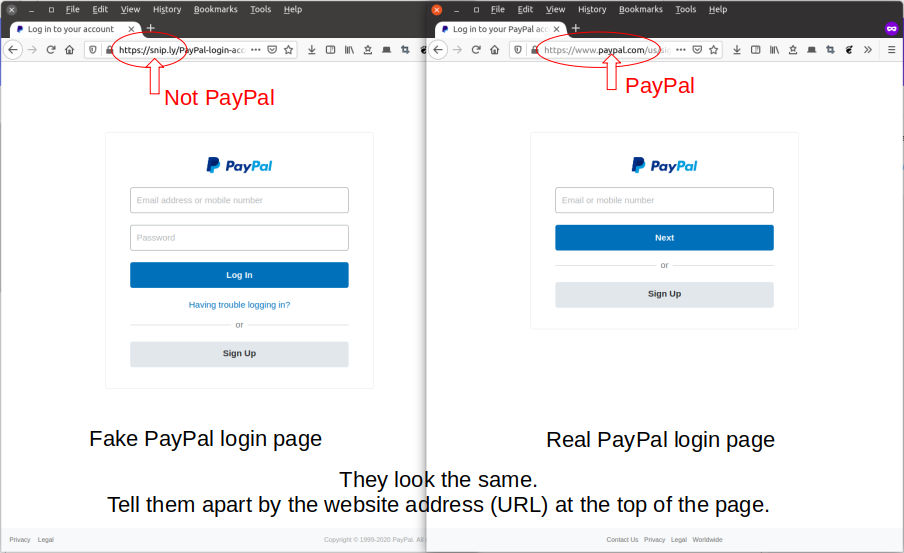
One thing that happens as advertisers get their algorithms into you is much more targeted advertising. Often times with a web link.
Ever wonder how long that website’s been around? Setting up shop, scamming money, and disappearing are tactics that have been around since scams. Long before the Internet. Checking how long a domain name has been around can help detect a scam.
One thing I do when I check advertising is check how old the domain name is. The domain name is the .com, .org, .gov, .net, etc., plus the word before it starting from the preceding / or ., whichever is closest before the .com. Examples like www.disney.com breakdown to domain name disney.com.
How old is the domain name disney.com?
The whois command reveals that information and more with 156 lines of output. The dates are among the first lines and are scrolled off the top of the screen. So scroll up to them to see them.
Substitute a function, called by the same name, that uses whois and grep to produce less output, and focused on dates and attributes like URLs. The substitute command returns 23 lines. These are the lines.
$ whois disney.com
Updated Date: 2021-01-21T15:04:59Z
Creation Date: 1990-03-21T05:00:00Z
Registry Expiry Date: 2023-03-22T04:00:00Z
NOTICE: The expiration date displayed in this record is the date the
currently set to expire. This date does not necessarily reflect the expiration
date of the domain name registrant's agreement with the sponsoring
view the registrar's reported date of expiration for this registration.
Updated Date: 2021-01-15T16:22:12Z
Creation Date: 1990-03-21T00:00:00Z
Registrar Registration Expiration Date: 2023-03-22T04:00:00Z
Registry Registrant ID:
Registrant Name: Disney Enterprises, Inc.; Domain Administrator
Registrant Organization: Disney Enterprises, Inc.
Registrant Street: 500 South Buena Vista Street, Mail Code 8029
Registrant City: Burbank
Registrant State/Province: CA
Registrant Postal Code: 91521-8029
Registrant Country: US
Registrant Phone: +1.8182384694
Registrant Phone Ext:
Registrant Fax: +1.8182384694
Registrant Fax Ext:
Registrant Email: Corp.DNS.Domains@disney.com
Easier to see only the dates and some other relevant info by customizing my own whois. I am sure it can be improved on, but for the time being this listing is the substitute whois in my .bash_aliases.
function whois {
if [ $# -ne 1 ]; then
printf "Usage: whois <domain.tld>\nTo use native whois precede command with \\ \n "
return 1
fi
# implemented code calls installation whois by full path
/usr/bin/whois $1 | grep -wi "date\|registrant\|contact
domain\|holder"
## haven't tried outside Ubuntu
## a possibility to make this somewhat portable
## $(which whois) $1 | grep -wi "date\|registrant\|contact
domain\|holder"
}Now, for an advertisement that’s been showing up in my Facebook feed lately, there’s listncnew.com. Sells NEW laptops and Macbooks for $75 – $95!! I figured it must be scam but, for that price, worth the risk because could cancel the credit card transaction. Before I made the order I ran the domain name through my substitute whois to see when the domain was registered. It was created October, 2021, very new. I didn’t expect to get my order and didn’t. At least I wasn’t out the money and now have a way to look at whois data that limits the output to show only information relevant to me.
whois listncnew.com
Updated Date: 2021-10-26T09:14:16Z
Creation Date: 2021-10-26T09:10:35Z
Registry Expiry Date: 2022-10-26T09:10:35Z
NOTICE: The expiration date displayed in this record is the date the
currently set to expire. This date does not necessarily reflect the expiration
date of the domain name registrant's agreement with the sponsoring
view the registrar's reported date of expiration for this registration.
Updated Date: 2021-10-26T09:13:25Z
Creation Date: 2021-10-26T09:10:35Z
Registrar Registration Expiration Date: 2022-10-26T09:10:35Z
Registry Registrant ID: 5372808-ER
Registrant Name: Privacy Protection
Registrant Organization: Privacy Protection
Registrant Street: 2229 S Michigan Ave Suite 411
Registrant City: Chicago
Registrant State/Province: Illinois
Registrant Country: United States
Registrant Postal Code: 60616
Registrant Email: Select Contact Domain Holder link
Admin Email: Select Contact Domain Holder link
Tech Email: Select Contact Domain Holder link
Billing Email: Select Contact Domain Holder link
This is my first post in a while. Haven’t been routine releasing posts this year. There’s another five that have been hovering in edit for a while. Maybe I can get them out before the end of this year.