Like many in the US I have only one ISP, Internet service provider, that can provide reasonable residential Internet upload and download speeds, e.g. >=200Mbps down, >=30Mbps up. That provider is Optimum. I’m not a gamer, don’t stream 4K, and almost never have more than one device streaming at a time so yes, >= 200Mbps down is reasonable for me.
To run this website from my home server I need the Optimum provided Altice Gateway (a combined cable modem and router) to have its router component set to bridge mode. My own router’s WAN port then gets a public IP address and that way I control NAT to the services I need. Optimum doesn’t provide access to the bridge mode setting for their gateway’s router so tech support must be contacted to have it set to bridge mode.
At this point I’ve had three gateways from Optimum. The first two gateways it took one or two days contact with support each time time to get the correct settings established. It was necessary to contact support, explain the router setting that needed to be made, and then follow up until it was actually working.
This third gateway, setup and config were nearly automatic, except of course, setting the router to bridge mode. As usual I contacted support to have the router set to bridge mode. It worked! My router got a public IP on the WAN port and everything was good to go. Then less than a week into the working setup it was no longer working. My router was getting a private IP on the WAN port. Checking my Optimum gateway on their website showed the router portion of the gateway had the LAN enabled and an address on that private LAN was what my WAN port was getting. Router working.
Call/text with support for more than three weeks trying to get them to set it back to the configuration I needed, the configuration it had been in for a short while after initial setup. Support even told me things like the problem was my router. The various techs I spoke/texted with continually blamed my router even though it was clear my router was getting a private IP address from the LAN configured in the Gateway’s router settings.
Every tech I spoke/texted with, their technical understanding of networking and their spoken English competency was not at the level needed for the work. It was clear basic networking wasn’t understood and also they would mistake words like “pass thru,” as “password.” I used “pass thru” while trying to explain (?explain? to tech support) what bridge mode meant. Getting them to recognize and acknowledge the problem was impossible, so I gave up. I decided to buy a cable modem to have both components needed to replace Optimum’s gateway.
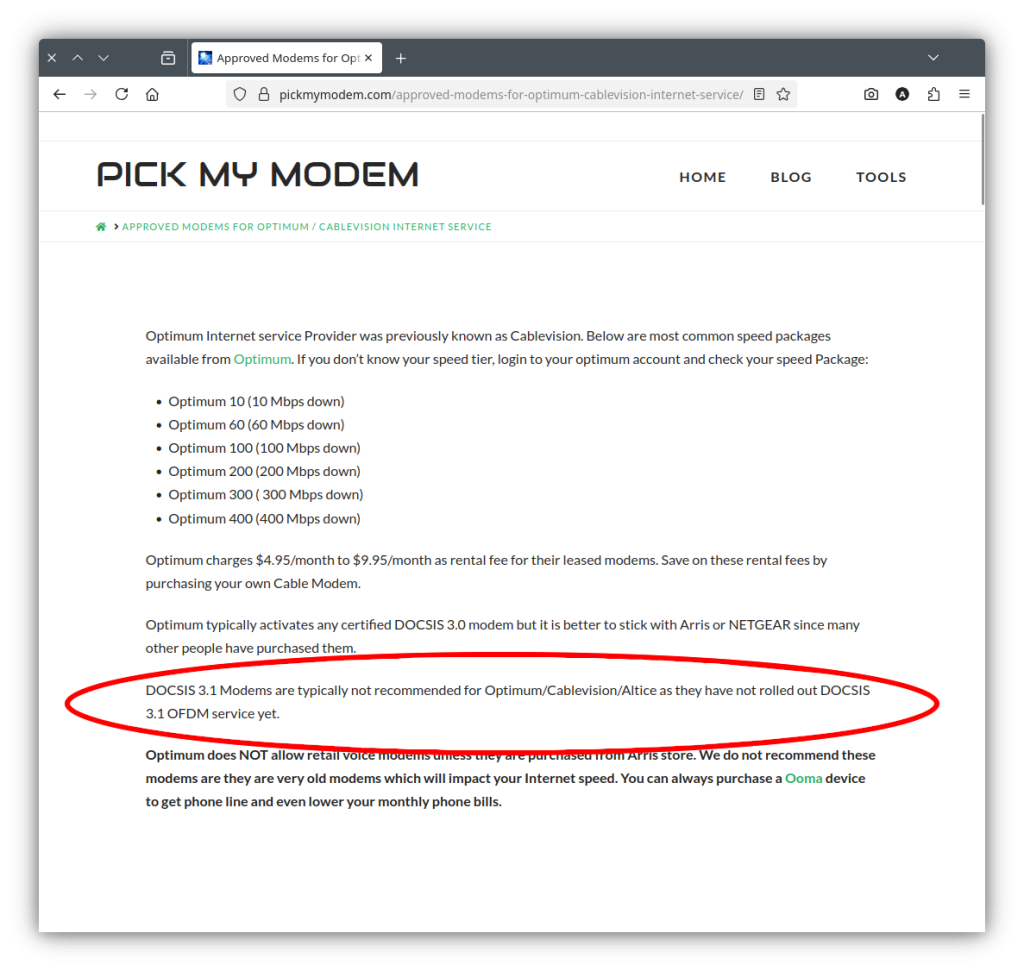
Even that was fraught with concern for me. Given the problems I’ve had with knowledgeable support I wanted to be certain the modem I buy could be activated by Optimum. I went to an Optimum store to ask about modems. They directed me to a website, pickmymodem.com, to identify a compatible modem. I pointed out it wasn’t their website and asked if the modem didn’t work would Optimum simply say, “not our website, too bad,” even though they had directed me there? Silence from across the counter.
Pickmymodem.com specifically states DOCSIS 3.1 modems are not recommended for Optimum.
Next I contacted Optimum’s modem activation number to ask about modem compatibility. On calling, the voice menu doesn’t offer an option to speak to “modem activation” even though the website specifically identifies that number for modem activation. So of course one must guess the appropriate menu option, talk to a bot that tries to “solve the problem” without connecting you to a person, then, after getting over that, eventually speak with someone.
When I finally spoke to someone they told me a DOCSIS 3.0 compatible modem was needed but had no information about specific modems and would not confirm whether a particular modem would work. I pointed out Optimum’s website says a DOCSIS 3.1 compatible modem is needed and DOCSIS 2.0 and 3.0 modems are not allowed on their network. Which information is correct, what you’re telling me, DOCSIS 3.0, or what the website shows, DOCSIS 3.1? Just silence from them, no answer.
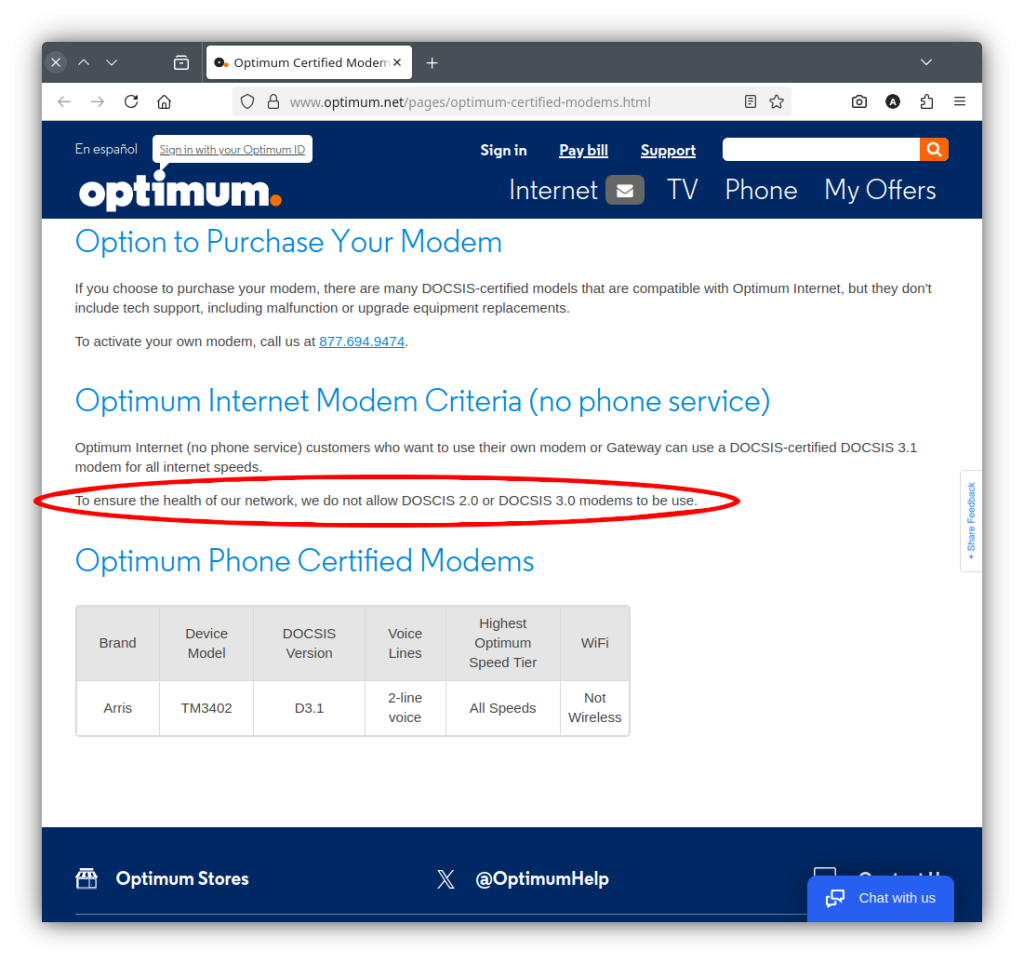
Optimum couldn’t/wouldn’t provide information about compatible modems, recommended a site they didn’t control to identify a modem, and between the website they recommended, their website and the Optimum support that I spoke with, gave conflicting information about what would work.
I gave up and just bought a DOCSIS 3.1 modem. The modem arrives and I’m amazed, amazed I say, activation went without a hitch! But this is Optimum so, of course, the trouble isn’t over.
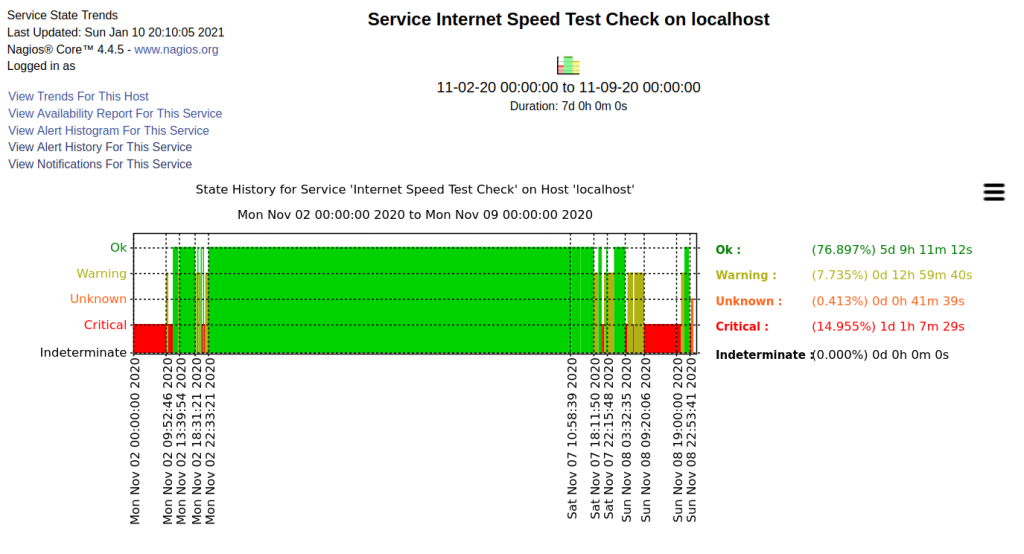
When we moved here about six years ago Optimum was and still is the only service provider for my address. Service was started at 200Mbps and that has was never realized. Slightly above 100Mbps was the typical speed. The first gateway eventually started failing and Optimum replaced it. A little over a month ago Internet connectivity became very poor on the second gateway. Optimum sent me a third gateway, bumped speed up to 300Mbps, and reduced the monthly service charge by $5. Nice, right?
Of course problems don’t stop there. I never saw close to 300Mbps. The best was usually around 150Mbps.
Throughout all this I’ve been on their website many times and note new customers are being offered 300Mbps for $40/month. I’m paying more than 3x that, even after the $5/month discount, for the same speed.
I call the retention department to ask to get my bill reduced to something in the $40/month range. Nope, no can do, the $5 was all I would get. What they would do was bump the speed to 1Gps and reduce the bill for that to $95/month for three years. I doubted their ability to deliver the service given their history but that was the only way to get the bill below $100/month so I accepted the offer.
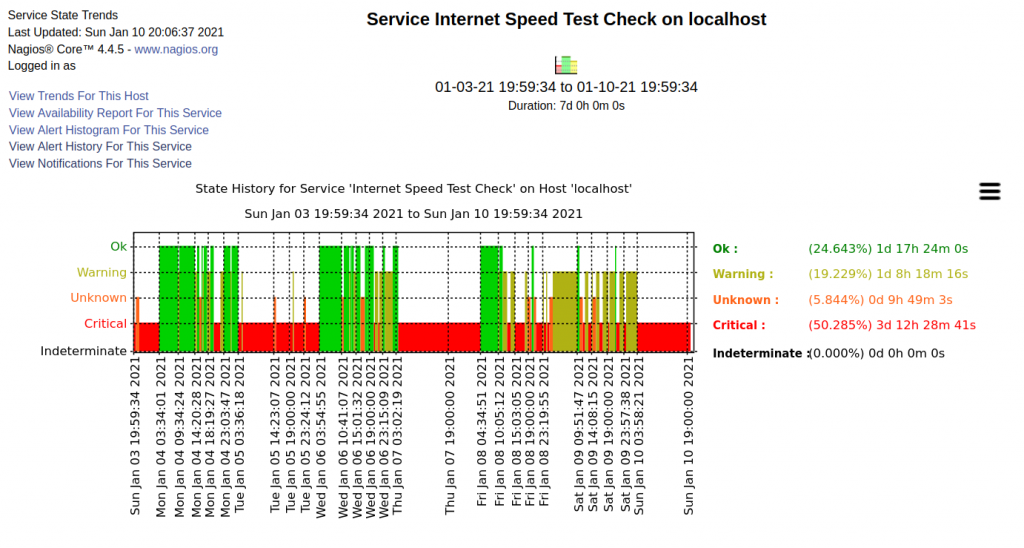
Next problem to resolve, I’ve supposedly got 1Gbps now but every speed test I’ve done until this morning tops out just below 200Gbps. This morning the speed tests across different test sites range from a low of 245Mbps to a high of 480Mbps. Better than I have had but still not even 50% of what’s supposedly being delivered.
I’m going to try and get the speed they’re supposedly giving me but I expect it won’t happen. They’ll tell me it is my equipment that’s the problem, I’m sure.
I expect the speed issue won’t be resolved and I’ll still hate Optimum after I try and get to the speed they say they’re providing. Have to wait see.